Jul. 13, 2020
Serverless Cloud Import System part 2
Part Two: Python Cloud Importer
By Asher Sterkin @BlackSwan Technologies
Introduction
Python Cloud Importer was developed as a part of the Cloud AI Operating System (CAIOS) project described at a high level in a separate article. Here, we are going to provide a more detailed account of motivation and internal design of this part of the system. This is the second part of a tri-part series organized as follows:
- Part 1: Linux FUSE Cloud Storage Mount — solution for a cloud-based IDE (e.g. AWS Cloud9)
- Part 2: Python Cloud Importer — solution for a serverless environment (e.g. AWS Lambda and Fargate)
- Part 3: Deployment Package Optimization — solution for optimal packaging between cloud function local storage, shared EFS and Cloud Storage
Part 3 is coming in the following week.
Acknowledgements
The major bulk of code was developed and tested by Anna Veber from BST LABS. Alex Ivlev from BST LABS made substantial contributions to Cloud 9 integration with goofys. Etzik Bega from BlackSwan Technologies was the first person on the Earth who realized Cloud Importer potential as an IP protection solution. Piotr Orzeszek performed an initial benchmark of the CAIOS Cloud Importer with heavyweight Open Source ML libraries and implemented the first version of Serverless news article classifier.
Yes, we follow the news
With the recent AWS announcement of supporting a shared file system for Lambda Function, the question of the viability of Cloud Import was immediately raised.
Does EFS support mean that the S3-based Cloud Importer value proposition is not viable anymore and its development should be decommissioned? The short answer is No.
To understand why we first need to cover the basics, covered in this part (Part 1), to understand how Python Cloud Importer works, covered here, and then to realize that the EFS support (Part 3) is just yet another packaging optimization option, sometimes useful, but by no means an ultimate one.
CAIOS Cloud Importer for Python
The Python importlib.abc Finder class hierarchy has the following structure:
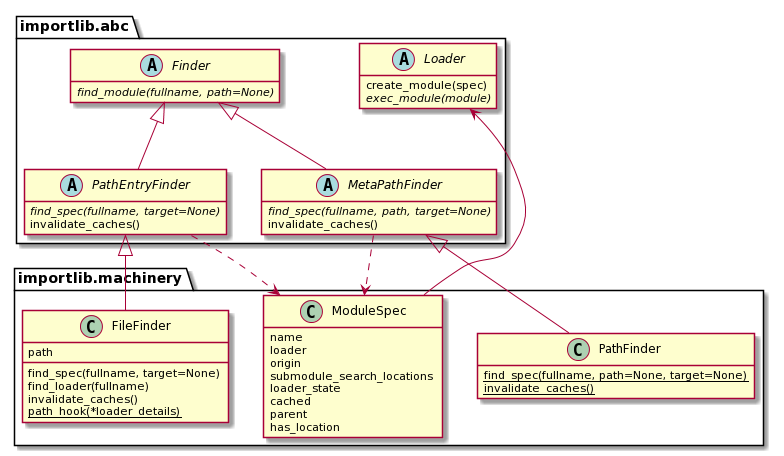
Fig 1: Python importlib.abc Finder Class Hierarchy
The Loader class hierarchy has the following structure:
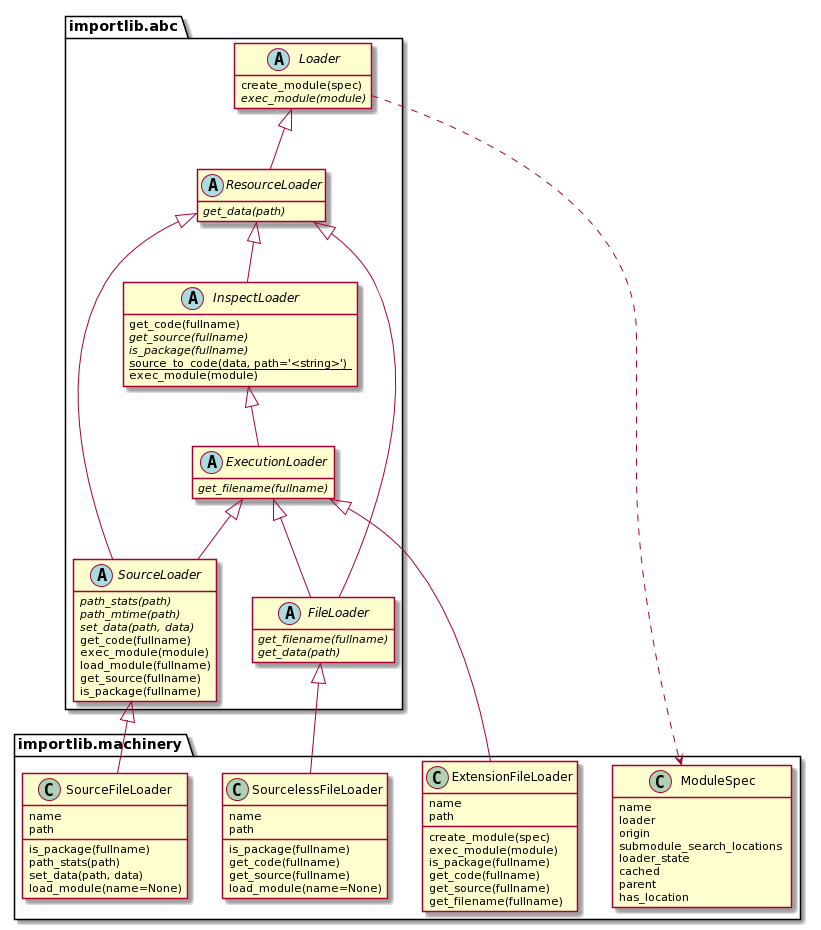
Fig 2: Python importlib.abc Loader Class Hierarchy
Nice and simple, heh? It took some time to crack this nut, but eventually, we were able to develop a custom Cloud Importer implementation.
CAIOS custom Python Cloud Finder design is presented below:
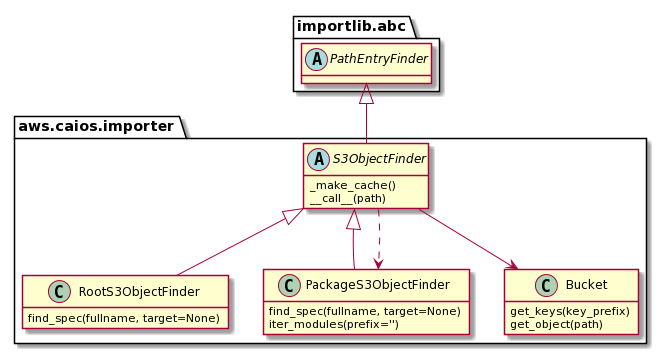
Fig 3: CAIOS S3ObjectFinder
CAIOS Python Cloud Loader design is presented below:
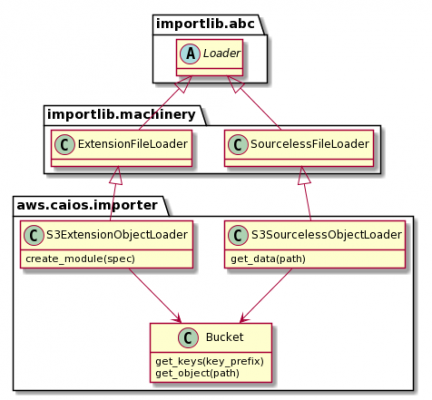
Fig4: S3ObjectLoader
In this implementation, the S3ObjectFinder, for every get_spec(self,fullname,target) call, obtains a list of keys from Bucket (we use an internal cache for speedup), scans through the list and tries to find the best matching key be it plain Python module, Python extension, package or namespace. Based on the match, for real Python modules, it will return a Spec pointing to either S3SourcesLessObjectLoader or S3ExtensionObjectLoader. We decided not to support the source object loader for security reasons.
Implementing the S3SourcessObjectLoader was relatively straightforward: download the object from S3 and pass byte stream to the parent SourcelessLoader class.
Implementation of the S3ExtensionObjectLoader was more involved. It’s not enough to download the object from an S3 Bucket, you also need to signal somehow to Linux that this is a Linux shared object. You also need to check whether this Linux Shared Object depends on some other Linux Shared Objects and to handle them all accordingly in the topological sort order. We eventually settled down using the Python cdll and elftools libraries to accomplish the task.
The current implementation downloads the Linux Shared Object files to the /tmp folder first, which somehow brings us back to the 250MB disk space limit (we have not encountered any ML library which requires so much for its shared objects so far) and incurs some extra latency. We are currently exploring some more efficient alternatives.
The current implementation of S3ExtensionObjectLoader is illustrated below:
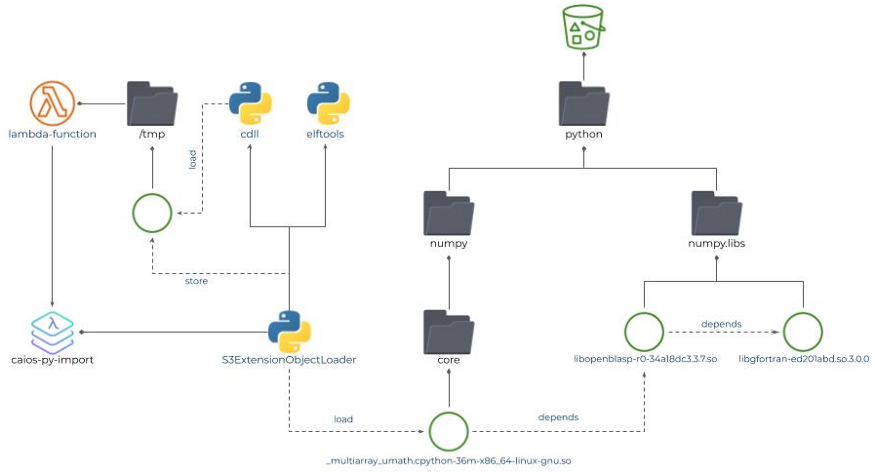
Fig 5: CAIOS S3ExtensionObjectLoader implementation
The basic usage of the Cloud Importer is fairly simple:

Patching 3rd Party Open Source Libraries
Once our Cloud Importer started working, we encountered an interesting problem: many libraries use direct file i/o to access internal configuration files or loop over available plug-ins dynamically. Of course, there is no file system for modules imported from S3, and many of them failed.
Proper solutions were found quite quickly — we need to patch these libraries to use more idiomatic Python facilities such as pkgutil.iter_modules(), pkgutil.get_data() and pkg_resources.resource_listdir(). So far, these simple changes were enough to onboard close to 50 most popular Python libraries. Should they want to, we will be willing to share our findings with Open Source library authors and provide further feedback.
CAIOS Cloud Importer Catalog
The S3ObjectFinder solution described above works reasonably well and is good when the list of Python libraries is not stable. In real production, however, this would seldom be the case. Open-Source Python libraries, especially heavyweight Machine Learning ones, do not change every minute and upgrading to a new version usually requires some careful backward compatibility verification.
Could we leverage this fact to reduce import latency? The answer is yes. We could build a simple catalogue that maps Python module full name into S3 object key, if any, and a corresponding Loader object in one shot.
The CAIOS Cloud Importer Catalog class hierarchy is presented below:
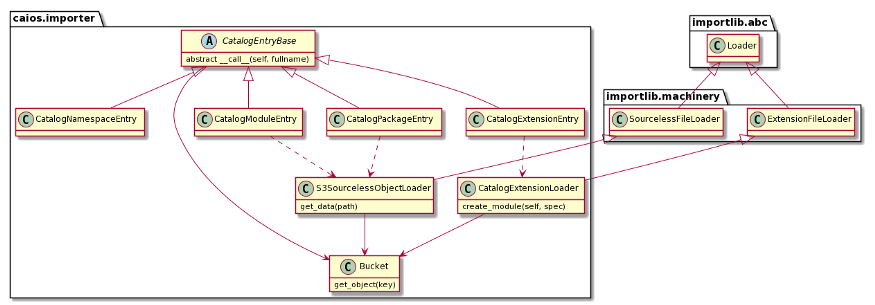
Fig 6: CAIOS Cloud Importer Catalog Class Hierarchy
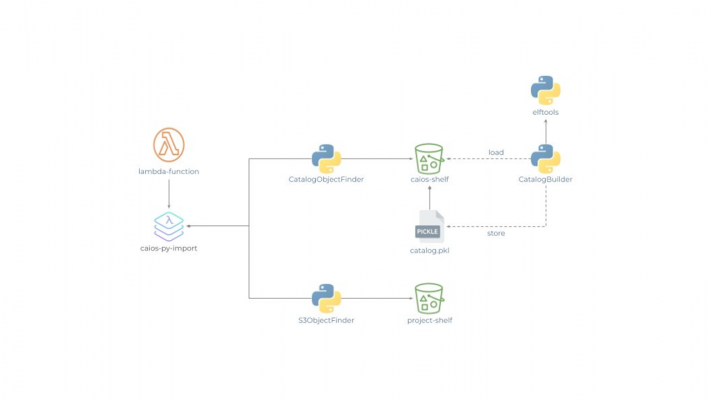
Now, we have flexibility: if S3 Bucket contains a catalogue file (simple pickled Python dictionary), then we will use catalogObjectFinder. Otherwise, we will use the S3ObjectFinder, as illustrated below:
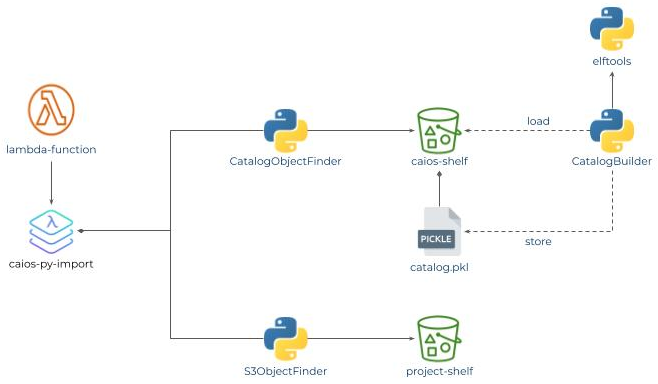
Fig 7: CAIOS Cloud Importer
Having a Cloud Importer for Python opens a lot of new possibilities. First, the same schema is easily extrapolated to other dynamic run-time environments such as Java, JavaScript or .NET. Second, there are a limitless number of additional optimizations such as bundling multiple modules, which are imported together anyhow, in one, m.b. compressed, S3 object. Third, we may start at last talking seriously about serverless inference and ETL for a much wider scope of practical use cases (so far that were more POC toys). Fourth, we could come up with a powerful Intellectual Property protection solution. And last, not least, we may start tracking actual usage of every Python module and provide valuable feedback to Open Source libraries authors. We will report about some of these exciting directions in the forthcoming Part 3 and following articles.
What’s Next?
Follow us on LinkedIn, Twitter, and Facebook, to be notified about coming news, announcements, and articles.


